7. Normalisatie
Door gegevens en gegevensgroepen te herschikken komt men tot een goed gestructureerde database waarin geen overtollige informatie zit.
Stap 1: verwijder alle procesgegevens (nulde normaalvorm)
Resultaten van berekeningen met de inhoud van andere velden kunnen steeds met een programmafunctie opnieuw uitgevoerd worden. Deze gegevens moeten niet opgenomen worden in de database.
Stap 2: verwijder herhalende deelverzamelingen (repeterende groepen) (eerste normaalvorm)
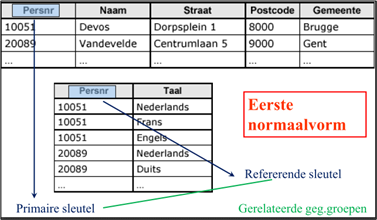
Als bv. in een veld “taal” (van de tabel “persoon”) verschillende talen worden ingevuld dan is dit een herhalende deelverzameling.
De herhalende deelverzameling wordt dan een aparte tabel (“taal”) met een refererende sleutel die verwijst naar de primaire sleutel van de oorspronkelijke tabel en een veld waarin de taal wordt vermeld (1 record per persoon/taal).
Een tweede voorbeeld:
lidnummer
naam
adresgegevens
kinderen (naam, leeftijd, gevolgde_lessen)
=> een lid kan meerdere kinderen hebben:
| lidnummer | lidnummer |
| naam | naam_kind |
| adres gegevens | leeftijd |
| | gevolgde_lessen |
=> een kind kan meerdere lessen gevolgd hebben:
| lid nummer | lid nummer | lid nummer |
| naam | naam_kind | naam _kind |
| adres gegevens | leeftijd | gevolg de_les |
Stap 3: verwijder attributen die functioneel afhankelijk zijn van een deel van de sleutel (tweede normaalvorm)
Sommige velden zijn slechts afhankelijk van een deel van de samengestelde primaire sleutel. Deze velden moeten in een aparte tabel geplaatst worden en het deel van de samengestelde sleutel waarvan ze afhankelijk zijn wordt toegevoegd.
Een voorbeeld:
=> nulde normaalvorm:
personeelsnummer
adresgegevens
uurloon
projecten (projectnummer, projectnaam, klantnaam, werkduur)
=> eerste normaalvorm:
| personeels nummer | personeels nummer |
| adres gegevens | project nummer |
| uurloon | project naam |
| | klant naam |
| | werkduur |
=> tweede normaalvorm:
| personeels nummer | personeels nummer | project nummer |
| adres gegevens | project nummer | project naam |
| uurloon | werkduur | klant naam |
Stap 4: verwijder attributen die functioneel afhankelijk zijn van andere attributen (derde normaalvorm)
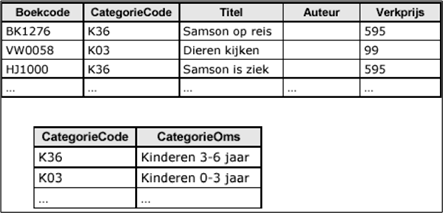
Het veld CategorieOms is gekend als de Categoriecode gekend is. De categorie omschrijving is afhankelijk van categoriecode. Het veld CategorieOms wordt in een aparte tabel geplaatst samen met de categoriecode.
Nadat de normalisatie stappen zijn doorlopen worden aan de gegevensgroepen een naam gegeven. Deze naam is tevens de tabelnaam. In het voorbeeld hierboven kan je dus 2 tabellen aanmaken: boek en categorie.